Bisher wurde IP im wesentlichen nur zur Vernetzung von fest an ein Netz angeschlossenen Computern genutzt. Damit war der Computermarkt der wesentliche Faktor für die Benutzung und das Wachstum des Internets. Dieses könnte sich in Zukunft durch neue Märkte ändern. Folgende Beispiele zeigen auf, in welchen Bereichen das Internet Protocol Verwendung finden könnte:
IPv4 war nicht für diese neuartigen Anwendungen konzipiert und kann diese allein schon wegen der geringen Zahl von Adressen nicht unterstützen. Es wäre ein gewaltiger Vorteil, wenn alle Anwendungen ein gemeinsames Protokoll benutzen könnten, welches für all diese Aufgaben geeignet ist.
Sowohl die Benutzer als auch die Anwendungen haben sich seit der Entwicklung des Internet Protocols grundlegend geändert. Das Internet wird zur Zeit weitestgehend kommerzialisiert. Geschäftsleute und Privatbenutzer werden immer mehr zur wichtigsten Benutzergruppe. Mit der Veränderung des Benutzer- und Anwendungsprofils (wie oben dargestellt) muß ein Basisprotokoll folgenden Anforderungen genügen:
Im Falle des Internet Protocols ist ein leichter, allmählicher Übergang von IPv4 auf eine neue Version des Internet Protocols notwendig. Dabei muß zu Anfang die Kommunikation zwischen den beiden Versionen möglich sein.
Es wurde der IETF klar, daß IPv4, auch mit kleinen Änderungen,
den oben genannten Anforderungen nie würde entsprechen können.
Um ein geeignetes Protokoll, das Internet Protocol der nächsten
Generation (IPng) zu finden, bat die IETF in RFC 1550 (Dezember 1993) um
Vorschläge. Aus den 21 eingehenden Vorschlägen kristallisierten sich
bis Dezember 1992 sieben ernsthafte Vorschläge heraus [Tan96].
Einige rieten, nur kleinere Änderungen an IPv4 vorzunehemen. Andere
rieten zu einer völligen Neuentwicklung. Ein weiterer Vorschlag war, das
OSI-ConnectionLess Network Protocol (CLNP) zu verwenden.
Über die Verwendung von CLNP wurde ernsthaft nachgedacht, hätte es doch die zwei größten Protokollfamilien zusammengeführt. Die 160-Bit Adressen hätten den größeren Adreßansprüchen genügt. CLNP ist IP recht ähnlich, war es doch nach IP modelliert worden. Doch die Verwendung von CLNP als das Internet Protocol der nächsten Generation (IP Next Generation) konnte aus zwei Gründen nicht verwirklicht werden:
Drei der anderen besseren Vorschläge wurden nach langer Diskussion
zu einem gemeinsamen Vorschlag zusammengeführt, dem
Simple Internet Protocol Plus. Dieses wurde, angeregt durch RFC 1752,
durch RFC 1883 zum Internet Protocol Version 6.
Die Versionsnummer 5 war bereits einem experimentellen
stream-basierten Protokoll, dem Internet STream Protocol Version 2(+)
(ST2(+)) [RFC 1190]/[RFC 1819] zugeordnet worden.
IPv6 erfüllt die oben genannten Anforderungen recht gut. Es erhält alle wesentlichen Vorteile von IPv4 und beseitigt dessen Nachteile oder schwächt diese zumindest ab.
IPv6 wurde unter folgenden Prämissen entworfen:
Die Neuerungen und Änderungen von IPv6 im Vergleich zu IPv4 lassen sich im wesentlichen unter folgenden Punkten zusammenfassen [RFC 1883]:
Die Adreßgröße wird von 32 Bit auf 128 Bit erweitert, um mehrere Hierachieebenen, eine größere Anzahl an adressierbaren Systemen und eine einfachere Adreßautokonfiguration zu ermöglichen. Multicast-Adressen werden um ein Bereichsfeld erweitert, mit dem die Ausbreitung des Multicasts angegeben werden kann. Außerdem wird ein neuer Anycast-Adreßtyp eingeführt, mit dem ein Paket zu einem System aus einer Menge von Systemen gesendet werden kann.
Einige IPv4-Header-Felder werden zu möglichen Header-Erweiterungen oder verschwinden ganz aus dem IPv6-Standard-Header, um die bei jedem Paket anfallenden Verarbeitungskosten zu reduzieren und um die Bandbreitenkosten für den IPv6-Header zu begrenzen.
Durch Änderung des Verfahrens IP-Header-Optionen einzufügen, können mehr und auch längere Optionen angegeben werden. Außerdem ermöglicht dieses Verfahren eine größere Flexibilität beim Einführen von neuen Erweiterungen in der Zukunft.
Es wird eine neue Möglichkeit eingeführt, Pakete eines speziellen Datenflusses, für die der Sender eine besondere Behandlung wünscht, zu kennzeichnen.
Erweiterungen zur Unterstützung der Authentizität, der Datenintegrität und der Geheimhaltung werden für IPv6 spezifiziert. Diese Optionen müssen alle IPv6-Implementierungen unterstützen.
Eine Schicht-2-Schnittstelle wird im weiteren Text zur besseren Lesbarkeit als ,,Interface`` bezeichnet. Aus dem gleichen Grund wurde der englische Begriff ,,Link`` dem Begriff Schicht-2-Verbindung vorgezogen. Die Verwendung der Begriffes ,,link-lokal`` und ,,site-lokal`` für ,,Schicht-2-beschränkt`` und ,,auf einen administrativen Bereich beschränkt`` wurde ebenso wegen der besseren Wiedererkennung in der englischsprachigen Literatur vorgezogen.
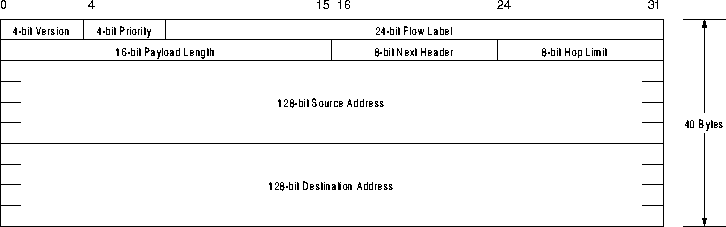
Dem drängendsten Problem von IPv4, dem zu kleinen Adreßraum, wird in IPv6 durch eine Vervierfachung der Adreßbits Rechnung getragen. IPv4-Adressen sind 32 Bit lang, während IPv6-Adressen 128 Bit lang sind.
Mit 32 Bit ließen sich bei optimaler Adreßvergabe theoretisch
Der Typ (siehe Seite ![]() ) einer IPv6-Adresse
wird durch die
führenden Bits in der Adresse bestimmt. Die Belegung der führenden Bits
sieht zunächst wie in Tabelle 1 angegeben aus [RFC 1884].
) einer IPv6-Adresse
wird durch die
führenden Bits in der Adresse bestimmt. Die Belegung der führenden Bits
sieht zunächst wie in Tabelle 1 angegeben aus [RFC 1884].
| Verwendung | Präfix (binär) | Teil des Adreßbereiches |
| Reserviert | 0000 0000 | 1/256 |
| Nicht zugeordnet | 0000 0001 | 1/256 |
| Reserviert für NSAP(OSI)-Adressen | 0000 001 | 1/128 |
| Reserviert für IPX-Adressen | 0000 010 | 1/128 |
| Nicht zugeordnet | 0000 011 | |
| bis | 001 | 29/128 |
| Provider-basierte Unicast-Adressen | 010 | 1/8 |
| Nicht zugeordnet | 011 | 1/8 |
| Reserviert für geographisch | ||
| basierte Unicast-Adressen | 100 | 1/8 |
| Nicht zugeordnet | 101 | |
| bis | 1111 1110 0 | 189/512 |
| Link-lokale Adressen | 1111 1110 10 | 1/1024 |
| Site-lokale Adressen | 1111 1110 11 | 1/1024 |
| Multicast-Adressen | 1111 1111 | 1/256 |
Insgesamt sind rund 30% des gesamten Adreßraumes von Anfang an belegt
oder reserviert,
für zukünftige Erweiterungen stehen noch 70% des Adreßraumes
zur Verfügung.
Alle Adressen mit 0000 0000-Präfix
sind für verschiedene Aufgaben,
z.B. Einbettung des IPv4-Adreßraumes reserviert. Es gibt Überlegungen,
IPX und NSAP-Adressen
direkt als IPv6-Adressen
zu unterstützen. Genaueres ist hier noch nicht festgelegt.
Die wichtigeren Adreßtypen werden weiter unten (Seite ![]() ) noch genauer vorgestellt.
) noch genauer vorgestellt.
Die Darstellung von IPv6-Adressen erfolgt nicht mehr im IPv4-üblichen ,,dotted decimal``-Format, da diese Schreibweise bei längeren Adressen doch sehr unübersichtlich und fehleranfällig wird. Eine IPv6-Adresse kann auf drei unterschiedliche Arten durch einen Textstring repräsentiert werden:
x:x:x:x:x:x:x:x
besteht aus 8 Bereichen, welche durch
Doppelpunkte voneinander getrennt sind. In jedem Bereich
werden 16 Bit hexadezimal dargestellt.
Beispiel:
Es ist nicht nötig, führende Nullen in die einzelnen Bereiche zu schreiben, aber es muß auf jeden Fall eine Ziffer in jedem der 8 Bereiche stehen.
kann verkürzt als
geschrieben werden. Andere Beispiele:
1989::8:800:200C:417A::1 (Loopback-Adresse, siehe unten):: (unspezifizierte Adresse, siehe unten)
x:x:x:x:x:x:d.d.d.d ist ebenfalls gültig, wobei die letzten
4 ´d´s mit dazugehörigen Punkten der Schreibweise für eine
IPv4-Adresse entsprechen. Beispiel:
oder in komprimierter Schreibweise:
IPv6-Adressen sind 128 Bit-Bezeichner für Interfaces und Mengen von Interfaces. Einem einzelnen Interface können eine oder mehrere IPv6-Adressen verschiedener Adreßtypen zugeordnet werden. Es gibt drei verschiedene Typen von Adressen [RFC 1884]:
Im Vergleich zu IPv4 sind Anycast-Adressen neu.
Unicast-Adressen sind Bezeichner für ein einzelnes Interface. Ein Paket, welches an eine Unicast-Adresse geschickt wird, wird genau an dem Interface zugestellt, welches durch die Adresse spezifiziert wird. Mehrere Adressen pro Interface müssen unterstützt werden.
Das Format einer IPv6-Provider-basierten Adresse ist ähnlich der Adreßform von IPv4 unter Classless Inter-Domain Routing (CIDR) aufgebaut. Sie hat folgendes Schema:
| 3 Bits | n Bits | m Bits | o Bits | 125-n-m-o Bits |
| 010 | Registry ID | Provider ID | Subscriber ID | Intra-Subscriber |
Es gibt zwei Arten von lokalen Adressen: link-lokale und site-lokale Adressen. Link-lokale Adressen sind für den Einsatz in einem einzelnen physikalischen Netz gedacht, während Site-lokale Adressen für den Einsatz in einem einzelnen administrativen Bereich gedacht sind.
| 10 Bits | n Bits | 118-n Bits |
| 1111111010 | 0..0 | Token-ID |
Link-lokale Adressen sind nur in dem Netz gültig, an welches ein Interface
direkt angeschlossen ist.
Sie ermöglichen die Adressierung in einem einzelnen physikalischen Netz.
Benutzt werden sie zur automatischen Konfiguration
(siehe auch Seite ![]() ),
Nachbarnentdeckung, oder wenn keine Router vorhanden sind.
Das Token muß so gewählt werden, daß dieses in dem
physikalischen Netz eindeutig ist. Bei Ethernet wird üblicherweise die
48-bit-IEEE-802 MAC-Adresse für diesen Zweck herangezogen.
Router dürfen keine Pakete mit link-lokalen
Adressen weiterleiten, da sonst Adreßkonflikte auftreten könnten.
),
Nachbarnentdeckung, oder wenn keine Router vorhanden sind.
Das Token muß so gewählt werden, daß dieses in dem
physikalischen Netz eindeutig ist. Bei Ethernet wird üblicherweise die
48-bit-IEEE-802 MAC-Adresse für diesen Zweck herangezogen.
Router dürfen keine Pakete mit link-lokalen
Adressen weiterleiten, da sonst Adreßkonflikte auftreten könnten.
| 10 Bits | n Bits | m Bits | 118-n-m Bits |
| 111111111011 | 0...0 | Subnetz-ID | Token |
Site-lokale Adressen können z.B. von Organisationen benutzt werden, welche (noch) nicht mit dem Internet verbunden sind. Wenn später die Organisation an das Internet angeschlossen wird, können globale Internet-dressen gebildet werden, indem der Site-lokale Präfix durch einen Subscriber-Präfix ersetzt wird.
Anycast-Adressen sind Bezeichner für eine Menge von Interfaces, welche typischerweise zu verschiedenen Systemen gehören. Ein Paket, welches an eine Anycast-Adresse geschickt wird, wird an eines der Interfaces zugestellt, welches durch die Adresse spezifiziert wird. Vom Standpunkt des Routingprotokolls gesehen ist dieses üblicherweise das ,,nächste`` Interface. Eine Anycast-Adresse ist ohne zusätzliche Informationen nicht von einer Unicast-Adresse zu unterscheiden.
Im Moment dürfen Anycast-Adressen keinem Endsystem zugeordent werden, nur zu Routern, da noch keine größere Erfahrung mit Anycast-Adressen vorliegt. Eine Anycast-Adresse darf nicht Quelle eines IPv6-Paketes sein.
Verschiedene Anycast-Adressen sind vordefiniert, z.B. die Subnetz-Router Anycast-Adresse. Hier definiert das Subnetz-Präfix mit angehängten Nullen die Adresse aller Subnetz-Router. Damit erreicht jedes Endsystem einen Router, so lange ein funktionsfähiger Router im Subnetz vorhanden ist.
Multicast-Adressen sind Bezeichner für eine Menge von Interfaces, welche typischerweise zu verschiedenen Systemen gehören. Ein Paket, welches an eine Multicast-Adresse geschickt wird, wird an alle Interfaces zugestellt, welche durch die Adresse spezifiziert werden. Multicast-Adressen haben ein spezielles Format (von Uni/Anycast unterscheidbar), welches unten genauer beschrieben wird. Multicast-Adressen dürfen nicht als Quelle eines IPv6-Paketes auftreten.
Multicast-Adressen haben folgendes Format:
| 8 Bits | 4 Bits | 4 Bits | 112 Bits |
| 11111111 | Flags | Wirkungsbereich | Gruppen-ID |
Die führenden 8 Einsen definieren eine Adresse als Multicast-Adresse.
Die oberen drei Bits des Flags-Feldes sind reserviert.
Mit Hilfe des untersten Flag-Bits kann definiert werden, ob eine
Multicast-Adresse nur temporär zugeordnet ist (Bit=1), oder ob es eine
dauerhaft durch die Internet Assigned Numbers Authority (IANA)
festgelegte Multicast-Adresse ist (Bit=0).
Mit Hilfe der Bits im Wirkungsbereichs-Feld kann der Wirkungsbereich einer
Multicast-Gruppe definiert werden. Tabelle 2 zeigt die
vorhandenen Möglichkeiten [RFC 1884]:
| Wert | Wirkungsbereich |
| 0 | reserviert |
| 1 | node-lokal |
| 2 | link-lokal |
| 3/4 | (nicht zugeordnet) |
| 5 | site-lokal |
| 6/7 | (nicht zugeordnet) |
| 8 | organisations-lokal |
| 9 bis D | (nicht zugeordnet) |
| E | global |
| F | reserviert |
Die Wirkung einer durch IANA festgelegten Multicast-Adresse ist unabhängig vom Bereich. Dies erlaubt eine flexible Erreichbarkeit.
Beispiel: angenommen, die Network Time Protocol-Servergruppe habe eine festgelegte Multicast-Adresse mit dem hexadezimalen Wert 43. Dann erreicht
FF01:0:0:0:0:0:0:43 alle NTP-Server in dem Rechner des SendersFF02:0:0:0:0:0:0:43 alle NTP-Server in dem physikalischen Netz des SendersFF05:0:0:0:0:0:0:43 alle NTP-Server in dem site-lokalen Bereich des SendersFF0E:0:0:0:0:0:0:43 alle NTP-Server des Internets
Die Wirkung einer nur temporär zugeordneten Multicast-Adresse
ist immer nur im angegebenen Bereich gültig.
Multicast-Gruppen werden mit Hilfe eines eigenen Protokolls, des Internet Group Management Protocols (IGMP) [Fen96] gebildet, verändert und aufgelöst.
Die Adresse 0:0:0:0:0:0:0:0 wird die unspezifizierte Adresse genannt. Diese darf nie einem
System zugeordnet werden. Sie zeigt die Abwesenheit einer anderen Adresse an.
Sie wird z.B. von sich initialisierenden Systemen benutzt. Diese
geben die unspezifizierte Adresse als Quelladresse von IPv6-Paketes an,
so lange die eigenen Adresse noch nicht bekannt ist.
Die Adresse 0:0:0:0:0:0:0:1 wird die Loopback-Adresse genannt. Diese kann
von einem System genutzt werden, um IPv6-Datagramme an sich selbst zu schicken.
Sie entspricht der IPv4-Adresse 127.0.0.1. Die Loopback-Adresse darf ebenfalls
nie einem System zugeordnet werden.
IPv6-Systeme, welche mit IPv4 kommunizieren wollen, benötigen eine IPv4-kompatible Adresse. Diese sieht wie folgt aus:
| 80 Bits | 16 Bits | 32 Bits |
| 0000.......0000 | 0000 | IPv4-Adresse |
Falls in einem IPv6-System Adressen eines nur-IPv4-Systemes dargestellt werden sollen, werden zur Unterscheidung von IPv4-kompatiblen IPv6-Adressen 16 Bits vor der IPv4-Adresse auf eins gesetzt.
| 80 Bits | 16 Bits | 32 Bits |
| 0000.......0000 | FFFF | IPv4-Adresse |
Damit ist immer klar, ob eine Adresse eine IPv6-Adresse ist, oder ob die Adresse nur als IPv4-Adresse verwendet werden darf.
Ein Ziel bei der Entwicklung von IPv6 war es, die Konfiguration von Endsystemen zu erleichtern. Zwei Verfahren, ein zustandsloses und ein dynamisches, unterstützen die automatische Konfiguration. Mit Hilfe dieser Verfahren erfahren Endsysteme ihre Adresse(n) sowie weitere Konfigurationsparameter.
Die beiden Verfahren unterscheiden sich in den externen Einflußmöglichkeiten. Das zustandslose Verfahren ermöglicht einfaches ,,plug and play``. Das aufwendigere dynamische Verfahren erlaubt eine genauere Konfiguration (z.B. Festlegung der verwendeten IP-Adressen) durch Systemadministratoren.
Beide Verfahren können kombiniert werden; ein Teil der benötigten Konfigurationsinformationen kann durch das zustandslose Verfahren erfahren werden, während andere Parameter durch das dynamische Verfahren konfiguriert werden können.
Das Autokonfigurationsverfahren wird durch das Setzen spezieller Felder in Router-Mitteilungen (Router Advertisements) bestimmt.
IPv6-Adressen werden einem Interface für eine feste Zeitspanne zugewiesen. Wenn die Lebenszeit einer Adresse abläuft, wird die Zuordnung (und die Adresse) ungültig. Die Adresse kann nun an ein anderes Interface vergeben werden. Um dieses Ablaufen von Adreßbindungen reibungsloser zu gestalten, durchläuft eine Adresse zwei verschiedene Phasen, während sie einem Interface zugeordnet ist. Zuerst ist eine Adresse vorzuziehen (preferred), welches bedeutet, daß ihre Benutzung keiner Restriktion unterliegt. Später wird eine Adresse dann als ungünstig eingestuft (deprecated). Dies kündigt an, daß die Adresse in Zukunft ungültig werden wird. Die Benutzung der Adresse ist zwar immer noch erlaubt, aber von der Verwendung wird abgeraten. Neue Verbindungen sollten, falls möglich, immer eine vorzuziehende Adresse benutzen.
Systeme stellen durch einen speziellen Test sicher, daß Adressen einmalig sind, bevor sie sie an ein Interface vergeben. Dieser Test wird unabhängig von dem Konfigurationsverfahren durchgeführt. Falls eine doppelte Adreßbenutzung erkannt wird, stoppt die automatische Konfiguration; die Konfiguration muß manuell durchgeführt werden.
Bei der zustandslosen Autokonfiguration werden keine Informationen über vergebene Adressen gespeichert. Zustandslose Autokonfiguration benötigt keine manuelle Konfiguration an den Endsystemen. Die Konfiguration beschränkt sich auf eine minimale (wenn überhaupt benötigte) Konfiguration der Router. Zusätzliche Server werden nicht benötigt.
Das zustandslose Verfahren erlaubt einem Endsystem seine eigenen Adressen zu erzeugen. Dies geschieht durch eine Kombination von lokal verfügbaren Informationen und Informationen, die durch Router verkündet werden. Router verkünden regelmäßig mit ihrer Existenz Adreß-Präfixe, welche das oder die Subnetze identifizieren, an denen ein Endsystem angeschlossen ist. Systeme kombinieren ein lokal eindeutiges Token (z.B. die Ethernet-Adresse) und die Adreßpräfixe, um gültige IP-Adressen zu erzeugen. Durch die Routermitteilungen wird festgelegt, welche anderen Informationen automatisch konfiguriert werden sollen. Um nicht auf diese Nachricht warten zu müssen, kann ein System auch eine spezielle Nachricht an alle verfügbaren Router schicken.
Wenn kein Router verfügbar ist, kann ein System nur link-lokale Adressen generieren. Dies reicht jedoch aus, um mit anderen an dem gleichen Netzsegment angeschlossene Systemen zu kommunizieren.
Genauere Informationen zur statischen System-Konfiguration können [Thom96] entnommen werden.
Mit Hilfe eines speziellen Protokolls, des Dynamic Host Configuration Protocols (DHCPv6) [Bou96], wird ein dynamisches Client/Server-Konfigurationsverfahren ermöglicht. Notwendig hierfür ist der Einsatz eines oder mehrer dezidierter DHCP-Server. Diese speichern Informationen über zu konfigurierende Endsysteme.
Die dynamische System-Konfiguration erfordert nicht unbedingt einen DHCP-Server in jedem Netzsegment. ,,Relay-Agents`` (Router) können eingesetzt werden, die Nachrichten von und zu zentralen DHCP-Servern weiterzuleiten.
Genauere Informationen zum DHCP-Protokoll für IPv6 können [Bou96] entnommen werden.
Die auf Seite 3.2 genannten Entwicklungsziele wirkten sich stark auf den IPv6-Header aus. Dort lassen sich folgende Änderungen zu einem IPv4-Header feststellen:

Dies ermöglicht Header, die insgesammt länger als 60 Byte (IPv4) sind.
Weiterhin ist es im Unterschied zu IPv4 nur der Quelle, nicht aber den an der Übertragung beteiligten Routern erlaubt, eine Fragmentierung einzuleiten. Deshalb soll die Maximum Transmission Unit (MTU) vor dem Versenden mittels Path MTU Discovery [McC96] ermittelt werden. Dabei handelt es sich um ein Verfahren mit dem unter Zuhilfenahme des Internet Control Message Protocol (ICMP) [RFC 1885] die MTU der gesamten Übertragungsstrecke ermittelt wird. Dies ermöglicht es den meisten Protokollen auf höheren Schichten, die Paketlänge so anzupassen, daß keine Notwendigkeit besteht zu fragmentieren.
Außerdem wird implizit in jedem Netz eine MTU von 576 Byte vorausgesetzt. Dort, wo diese Annahme nicht erfüllt ist, muß mit geeigneten Mechanismen auf Schicht 2 fragmentiert werden.
Die hohen Verarbeitungskosten, die durch Fragmenierung entstehen, sollen auf diese Weise vermieden werden.
Dies wurde unter IPv4 auch schon so gehandhabt, obwohl laut Standard [RFC 791] eigentlich die Zeit in Sekunden angegeben werden sollte, so daß es genaugenommen nur einer Umbenennung hin zur realen Verwendung des Feldes gleichkommt.
Es ist zur Zeit auch kein anderer Mechanismus, insbesondere als Header-Erweiterung, vorgesehen. Indirekt könnte man dies jedoch mit dem Authentication-Header verwirklichen (siehe 3.8.4).
Damit werden Abarbeitungskosten, die bei IPv4 mit jedem Paket entstehen, eingespart. Das Weglassen dieser Überprüfung ist möglich, da heutzutage die Schicht-2-Verbindungen sicherer sind, oder zumindest in ihrer Schicht Verfahren implementieren, um vorhandene Übertragunsfehler zu erkennen. Zudem findet üblicherweise in einer höheren Protokollschicht die Überprüfung aller Daten statt [RFC 1883].
Dies soll mit neuen 64-bit-Architekturen in Netzknoten eine Effizienzsteigerung ermöglichen.
Mit dem Priority-Feld ist es einer Quellstation möglich, die Beförderungspriorität seiner Pakete relativ zu seinen anderen Paketen zu bestimmen. Die Prioritätswerte sind in zwei Bereiche unterteilt: Werte von 0 bis 7 werden benutzt, um Datenverkehr zu kennzeichnen, bei dem die Quelle Flußregelung bereitstellt (z. B. TCP). Werte von 8 bis 15 werden verwendet, um Datenverkehr zu kennzeichnen, bei dem Daten mit einer konstanten Übertragungsrate übertragen werden (z. B. Echtzeit-Anwendungen).
Die empfohlenen Prioritätswerte spezieller Anwendungskategorien sind für flußgesteuerte Übertragungen in Tabelle 3 aufgeführt.
| Priorität | Anwendungsbereich |
| 0 | nicht charakterisierter Datenverkehr |
| 1 | ,,Füll``-Übertragungen (z. B. netnews) |
| 2 | Anwendungen mit kleinem Datenverkehr (z. B. email) |
| 3 | (reserviert) |
| 4 | Anwendungen mit großem Datenverkehr (z. B. FTP, NFS) |
| 5 | (reserviert) |
| 6 | interaktive Anwendungen (z. B. telnet, X) |
| 7 | Internet Kontrollverkehr (z. B. Routing-Protokolle, SNMP) |
Bei nicht flußgesteuerten Übertragungen sollte der niedrigste Prioritätswert (8) verwendet werden, falls Daten bei Überflutung verworfen werden können (z. B. bei hochwertigen Videoübertragungen). Der höchste Prioritätswert (15) soll dann angewendet werden, wenn möglichst keines der gesendeten Pakete verloren gehen soll (z. B. bei minderwertigen Audioübertragungen). Zwischen den Prioritäten für flußgesteuerte und nicht flußgesteuerte Übertragungen existiert keine implizite Ordnung. D. h. Pakete mit Prioritäten aus dem einen Bereich dürfen nicht mit Paketen, die eine Priorität aus dem anderen Bereich haben, in Relation gesetzt werden.
Durch dieses Feld im Header haben Endsysteme und vor allem Router eine Möglichkeit den Vorrang von Paketen (im gleichen Prioritätsbereich) aus dem aktuellen Datenverkehr zu ersehen.
Das Feld Flow Label im IPv6-Header kann von einer Quelle zur
Flußkennzeichnung von Paketen benutzt werden. Als Fluß wird hierbei eine
Menge von Paketen bezeichnet, die von einer einzelnen Quelle zu einem
bestimmten Ziel![]() gesendet werden, für die die Quelle eine spezielle Behandlung durch die
IPv6-Router wünscht. Dies kann sie z. B. bei besonderen
Quality-of-Service-Merkmalen oder Echtzeit-Service verwenden. Die Art der
speziellen Behandlung kann dabei über ein eigenes Protokoll, wie z. B. dem
Resource Reservation Protocol (RSVP), oder über IPv6-Header-Erweiterungen
(siehe 3.8) geschehen, wie z. B. mit dem Hop-by-Hop
Options-Header (siehe 3.8.2).
gesendet werden, für die die Quelle eine spezielle Behandlung durch die
IPv6-Router wünscht. Dies kann sie z. B. bei besonderen
Quality-of-Service-Merkmalen oder Echtzeit-Service verwenden. Die Art der
speziellen Behandlung kann dabei über ein eigenes Protokoll, wie z. B. dem
Resource Reservation Protocol (RSVP), oder über IPv6-Header-Erweiterungen
(siehe 3.8) geschehen, wie z. B. mit dem Hop-by-Hop
Options-Header (siehe 3.8.2).
Der Einsatz dieses Merkmals des IPv6-Protokolls wird im Moment noch experimentell erpropt. Aussagen über die Verwendung des Flow Labels sind erst möglich, wenn man genaue Aussagen über die Notwendigkeit der Flußsteuerung im Internet machen kann. Die Entwicklung des Resource Reservation Protocols, welches zur Zeit als Draft [Bra96b] vorliegt, wird hierzu einen Teil beitragen.
Systeme, die die Funktion des Flow Labels nicht unterstützen, müssen es auf null setzen, wenn sie Pakete erzeugen, bzw. unverändert lassen, wenn sie Pakete weiterleiten, und ignorieren, wenn sie Pakete empfangen.
Das Flow Label wird von der Quelle des Datenstroms den Paketen zugewiesen. Es können mehrere aktive Flow Labels zwischen einer Quelle und einem Ziel existieren, wie auch Datenverkehr, der keinem bestimmten Fluß zugeordnet ist. Ein Datenstrom wird genau gekennzeichnet durch die Kombination der Quelladresse und dem Flow Label, welches ungleich null ist. Pakete, die zu keinem Datenfluß gehören, haben ein Flow Label von null.
Neue Flow Labels müssen pseudo-zufällig und gleichverteilt im Bereich von 1 bis FFFFFF ausgewählt werden. Dies hat den Sinn, daß es Routern möglich sein sollte, das Flow Label als Hash-Schlüssel zu benutzen, um den mit dem Fluß verbunden Status zu finden. Aus diesem Grund darf eine Quelle auch ein Flow Label nicht verwenden, solange das alte noch Gültigkeit hat. Die Gültigkeit endet 6 Sekunden nach dem letzten Paket.
Alle Pakete eines Datenflusses müssen mit der gleichen Quelladresse, Zieladresse, Priorität und Flow Label versendet werden. Enthalten Pakete einen Hop-by-Hop Options-Header, so muß dieser bei allen Paketen den gleichen Inhalt haben. Bei Verwendung eines Routing Headers müssen alle Optionen bis einschließlich des Routing Headers gleich sein. Router können, müssen aber nicht, diese Bedingungen überprüfen, und sollten bei Entdeckung eines Fehlers eine ICMP-Fehlermeldung an den Sender schicken.
Mit IPv6 wird ein neuer Mechanismus eingeführt, mit dem zwischen den Standard-IPv6-Header und denen der höheren Protokollschichten zusätzliche Header(-Erweiterungen) plaziert werden können. Die Art des folgenden Headers wird im Next Header-Feld angegeben. Wie in Abbildung 5 gezeigt, kann ein IPv6-Paket keine, eine oder mehrere Header-Erweiterungen enthalten.
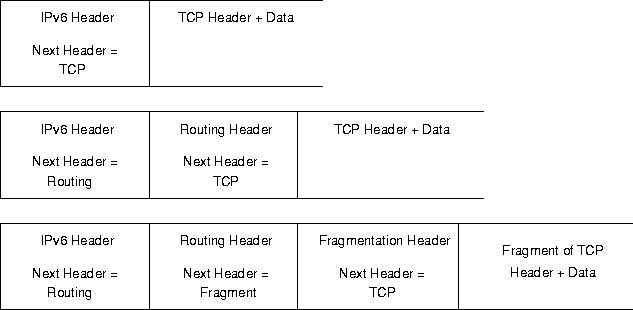
Abbildung 5: Anordung von
Header-Erweiterungen
Mit Ausnahme des Hop-by-Hop Options-Headers werden die zusätzlichen Header nicht untersucht oder abgearbeitet bis das Paket an seinem Ziel angekommen ist. Ziel eines Paketes können ein oder mehrere Endgeräte sein, je nachdem ob eine Unicast-, Anycast- oder Multicast-Adresse angegeben wurde. Durch diese Vorgabe werden die Prozeßkosten für Pakete mit Header-Erweiterungen niedrig gehalten.
Normalerweise wird das Next Header-Feld des IPv6-Headers entschlüsselt und dann die erste Header-Erweiterung verarbeitet bzw. der Header einer höherliegenden Protokollschicht, falls keine Option angegeben wurde. Anhand des Inhalts und der Semantik jeder Header-Erweiterung wird entschieden, ob der nächste Header abgearbeitet wird oder nicht. Daher müssen die Header-Erweiterungen immer in der Reihenfolge ihres Auftretens abgearbeitet werden. Es ist nicht erlaubt, alle Header zu lesen und die Ausführungsfolge zu verändern.
Eine andere Verbesserung zu IPv4 ist, daß die IPv6-Header-Erweiterungen eine beliebige Länge haben können und daß es keine Beschränkung bezüglich der gesamten Länge von Optionen auf insgesamt 40 Bytes gibt.
Durch diese Verbesserungen können mit IPv6 Optionen verwendet werden, die in IPv4 in der Praxis nicht, oder zumindest nicht zusammen, eingesetzt werden können. Ein Beispiel hierfür sind die IPv6 Authentifizierungs- und Geheimhaltungsoptionen und die Routing Option.
Um die Abarbeitungsgeschwindigkeit von nachfolgenden Headern und des darauffolgenden Transportprotokolls zu erhöhen, sind alle Erweiterungen ein Vielfaches von 64 Bits lang.
Im Augenblick sind für IPv6-konforme Implementierungen die in Tabelle 4 aufgelisteten Header-Erweiterungen definiert [RFC 1883].
| Header-Erweiterung | Funktion |
| Routing (Type 0) | Erweitertes Routing (wie IPv4 Source Routing) |
| Fragmentation | Fragmentierung und Reassemblierung |
| Authentication | Authentifizierung und Integrität |
| Encapsulating Security Payload | Geheimhaltung |
| Hop-by-Hop Options | Spezielle Optionen, welche von jedem Rechner abgearbeitet werden müssen |
| Destination Options | Optionale Informationen, welche nur vom Zielrechner untersucht werden müssen |
Enthält ein Paket mehr als eine Header-Erweiterung, so sollten diese in folgender Reihenfolge verwendet werden:
Jeder Header-Typ, bis auf die Ausnahme des Destination Options-Header, sollte nur einmal in einem Paket enthalten sein. Dieser kann maximal zweimal verwendet werden, einmal vor dem Routing-Header und einmal vor dem Header der höheren Protokollschicht.
Bei Verwendung vor dem Routing-Header muß jedes System, welches durch eine Adresse dort referenziert wird, diese Option (es können auch mehrere sein) verarbeiten. Das Paket kann darüberhinaus noch über weitere Vermittlungsysteme zugestellt werden (Loose Source Routing), die nicht im Routing-Header aufgeführt sind. Diese dürfen die Option jedoch nicht verarbeiten.
Beim Hop-by-Hop Options-Header hingegen muß jedes System, welches das Paket empfängt, die dort angegebene Option beacheten. Wird der Destination Options-Header vor der höheren Protokollschicht plaziert, so muß nur das Zielsystem die Option verarbeiten.
Wird eine neue Header-Erweiterung definiert, so muß für diese die Einordnung relativ zu den bisher definierten spezifiert werden.
Im Hop-by-Hop Options-Header und Destination Options-Header werden optionale Informationen transportiert, die von bestimmten Systemen auf dem Weg zum Zielsystem untersucht werden müssen. Beide haben folgendes Format:

Das Next Header-Feld hat hier die übliche Bedeutung, indem es den Typ des folgenden Headers spezifiziert, und das Hdr Ext Len-Feld gibt die Länge des Headers in 64-bit-Einheiten an. Da die Header immer auf 64 Bit ausgerichtet werden, werden die ersten 64 Bit nicht gezählt.
Danach werden eine oder mehrere Optionen mittels des type-length-value-Verfahrens (TLV) angegeben (Abbildung 7).
Wie der Name schon suggeriert, wird zuerst im Option Type-Feld die Art der Option, im Option Data Length-Feld die Länge dieser in Bytes und schließlich noch die eigentliche Option angegeben.
Im Option Type-Feld ist noch implizit mit den höchstwertigen 3 Bits angegeben, wie ein System verfahren soll, wenn es die angegebene Option nicht versteht, und ob sich in dieser Option die Daten während einer Übertragung ändern können. Dies ist wichtig für Verschlüsselungsalgorithmen, die gegebenenfalls dann diese Option aussparen müssen.
Zur Zeit sind für beide nur zwei Padding-Optionen, welche eine Ausrichtung in Byte-Schrittweite erlauben, und für den Hop-by-Hop Options-Header noch zusätzlich die Jumbo Payload-Option (Abbildung 8) spezifiziert.
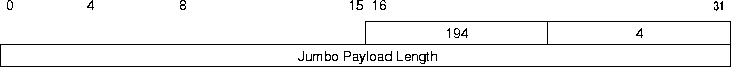
Abbildung 8: Jumbo Payload Option
Mit dieser ist es möglich Pakete zu verschicken, die mehr als 65535 Byte Nutzdaten enthalten. Dies stellt eine sinnvolle Erweiterung für die Übertragung von sehr großen Datenmengen dar. Eine gleichzeitige Verwendung der Jumbo Payload Option und eines Fragmentation-Headers ist nicht erlaubt, da sich dies widerspricht.
Konkret würde ein Hop-by-Hop Options-Header mit Jumbo Payload Option, wie in Abbildung 9 dargestellt, verwendet werden.
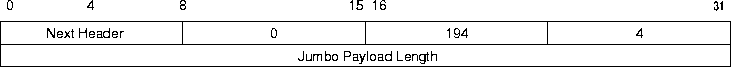
Das Routing von IPv6 ist fast identisch zu dem in IPv4 unter CIDR (siehe 2.2). Ausgenommen ist die Tatsache, daß der Adreßraum 128 Bit groß ist. Mit wenigen Erweiterungen sollten alle IPv4-Routingalgorithmen (OSPF, RIP, IDRP, ISIS usw.) auch unter IPv6 verwendet werden können. IPv6 beinhaltet auch einfache Routingerweiterungen, mit denen neue Funtionalitäten erreicht werden. Diese Möglichkeiten beinhalten:
Die neue Routing-Funktionalität wird erreicht, indem eine Sequenz von IPv6-Adressen mittels des IPv6 Routing-Headers angegeben wird. Der Routing Header wird von einer Quelle benutzt, um zwischengelagerte Systeme (oder topologische Gruppen) anzugeben, welche von einem Paket auf dem Weg zum Zielsystem ,,besucht`` werden müssen. Diese Funktionalität ist sehr ähnlich der von IPv4 Loose Source and Record Route Option und Strict Source and Record Route Option [RFC 791]. Der Unterschied besteht darin, daß nicht für die Routing-Option generell angegeben werden muß, ob das Loose oder Strict Verfahren verwendet werden soll, sondern daß die Angabe für jede Adresse gesondert möglich ist.
Oft ist ein System daran interessiert auf Pakete zu antworten. Daher ist es meistens erforderlich, daß ein System die angegebene Reihenfolge der Adressen umkehrt, um so Pakete zum Absender zurückschicken zu können. Dieses Vorgehen ist in IPv6 der Standardfall. Will man sichergehen, daß die Adressen während der Übertragung nicht verändert worden sind, so kann man zusätzlich den Authentication-Header (siehe 3.8.4) benutzen.
Diese grundsätzliche Vorgehensweise ist nötig, damit Systeme solche neuen Möglichkeiten wie die Auswahl von Dienstanbietern und Verwendung der neuen Adreßmöglichkeiten anwenden können.
In den drei folgenden Beispielen soll gezeigt werden, wie man die Adreßsequenzen verwenden kann. Hierbei wird eine Adreßsequenz durch einzelne Adressen, getrennt durch Kommata, dargestellt. Zum Beispiel:
SRC, I1, I2, I3, DST
Nehmen wir an, zwei Systeme H1 und H2 (Abbildung 10) wollen miteinander kommunizieren und sind mit den Providern P1 und P2 verbunden. Ein dritter Provider PR, für drahtlose Systeme, ist mit den beiden anderen Providern P1 und P2 verbunden.
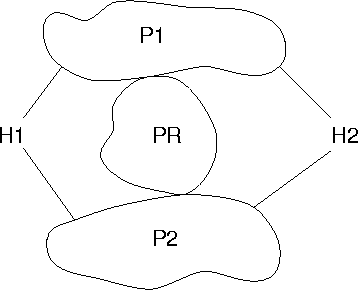
Im einfachsten Fall, also ohne Verwendung von Adreßsequenzen, enthält ein Paket die Adressen:
H1, H2
H2, H1
H1, P1, H2
H2, P1, H1
H2, P2, P1, H1
H1, PR, P1, H2
H2, P1, PR, H1
Wie man aus den Beispielen entnehmen kann, wird durch die Angabe von Adreßsequenzen mit dem IPv6 Routing Option Header die Auswahl von Dienstanbietern, Mobilität und Readressierung ermöglicht. Dies ist ein einfaches, aber trotzdem mächtiges Verfahren. Hierbei könnte insbesondere der neue Anycast-Adreßtyp verwendet werden, mit dem es Dienstanbietern ermöglicht wird, die Adressen für Gateways zu oder von anderen Netzen zu vereinheitlichen.
Es werden zwei Möglichkeiten angeboten um Sicherheitsaspekte zu unterstützen. Jede wird durch einen eigenen Header realisiert.
(AH) ist entwickelt worden, um Integrität und Echtheit eines IP-Datagrammes überprüfen zu können [RFC 1826]. Geheimhaltung der Daten ist damit nicht realisiert. Dadurch wird erhofft, daß der Authentication-Header in weiten Teilen des Internets Verbreitung findet, auch in Gebieten und Ländern, in denen Geheimhaltung mittels Verschlüsselung verboten ist.
Mit dem Authentication-Header kann man Sicherheit zwischen Endsystemen, zwischen zwei oder mehreren Gateways und einer Menge von Endsystemen oder Gateways realisieren.
Ein Security Gateway ist ein System, welches den Kommunikationszugang zu externen nicht glaubwürdigen und internen glaubwürdigen Systemen herstellt. Hierbei ist gedacht, daß das Security Gateway den vertrauenswürdigen Systemen einen Sicherheitsdienst anbietet, um mit nicht vertrauenswürdigen externen Partnern zu kommunizieren. Von dem vertrauenswürdigen Teilnetz muß natürlich angenommen werden können, daß sich alle Systeme (wie Endgerät und Router) vertrauen, aber auch, daß die unterliegenden Kommunikationkanäle nicht angegriffen werden können. Ist ein solches Securtiy Gateway vorhanden, können alle internen Systeme den Sicherheitsdienst in Anspruch nehmen und brauchen daher den Authentication-Header nicht zu implementieren.
Dies wird wohl am häufigsten bei IPv4-Systemen der Fall sein, da IPv6 die Unterstützung des Authentication-Headers verpflichtend vorschreibt. Andererseits kann durch das Gateway im internen Netz auf die Verwendung des Authentication-Headers verzichtet werden, um dadurch die Protokollast zu veringern. Trotzdem besteht so bei Kommunikation nach außen über das Gateway die Möglichkeit, sichere Verbindungen zu unterhalten.
(ESP) sichert in erster Linie die Geheimhaltung, aber mit gewissen Algorithmen kann er zusätzlich auch Integrität und Echtheit der Daten sichern [RFC 1827]. Aus gesetzlichen Gründen darf dieser Mechanismus oder der verwendete kryptographische Algorithmus aus manchen Staaten nicht exportiert und in anderen Staaten nicht importiert verwendet werden.
Auch hier bietet es sich an, Security Gateways zu verwenden. Damit kann man über ein unsicheres Weitverkehrsnetz, wie das Internet, ein virtuelles privates Netz bilden. Dies stellt zwar keinen Ersatz für die Geheimhaltung von End- zu Endsystem dar, aber dazu kann der Encapsulating Security Payload-Header zusätzlich von diesen verwendet werden.
Beide Header sind fester Bestandteil der IPv6-Spezifikation. Trotzdem ist man bemüht, eine Lösung zu finden, mit der auch IPv4-Implementation diese Funktionalität benutzen können. In beiden Möglichkeiten kann der kryptographische Alogrithmus ausgetauscht werden, ohne daß andere Teile der Implementation verändert werden müssen.
Ein Key Management-Protokoll ist noch nicht vereinbart, aber Vorschläge existieren bereits. Die beiden Header Typen sind nur durch den Security Parameters Index (SPI) mit dem Key-Management verbunden. Daher kann man sie defineren, ohne den Mechanismus zu kennen [RFC 1825].
Beide Header-Typen können kombiniert werden. Im Unterschied zu IPv4 müssen alle IPv6-Systeme diesen Dienst mindestens mit dem MD5-Algorithmus mit einem 128-bit-Schlüssel unterstützen. Optional ist zur Zeit die Unterstützung für andere Algorithmen, obwohl sicher ist, daß MD5-Verschlüssselung sehr hohe Verarbeitungskosten erzeugt und somit die Übertragung merklich verlangsamt.
Will man die Echtheit der Datagramme auch von Zwischenstationen überprüfen lassen, so muß beachtet werden, daß die Pakete nicht fragmentiert werden, z. B. bei zwischenliegenden IPv4 Stationen. (Anwendung von Path MTU Discovery)
Bei IPv6 ist der Authentication-Header normalerweise nach dem Hop-by-Hop und vor dem IPv6 Destination Options angeordnet.